Introduction
Les services d’intégration continue sont des outils permettant au système de développement de valider la non-régression du code source sans la nécessité d’imposer l’exécution manuelle des tests aux développeurs.
Il est à noter qu’en plus des tests, les services d’intégration continue moderne peuvent automatiser un grand nombre de tâches. Par exemple les tâches de compilation, de livraison, de déploiement et d’inspection (monitoring) peuvent être faites à l’aide de ces outils.
Pourquoi utiliser les services d’intégration continue dans le logiciel libre
Il est d’autant plus important de bien tester la non-régression des logiciels libres puisque ces derniers encouragent la participation du plus grand nombre au développement du logiciel. Sans service d’intégration continue, les administrateurs de dépôt d’un logiciel ayant une grande popularité se verront rapidement dépassés par les événements.
Ainsi, en instaurant une politique de « merge/pull » request basée sur le résultat d’un service d’intégration continue, les administrateurs de dépôt peuvent diminuer au maximum les tâches à effectuer durant le « merge/pull ».
Types de tests à implanter
En général, le minimum qu’un service de développement continu devrait avoir à faire est:
- La compilation du projet (si nécessaire);
- L’exécution des tests unitaires;
- L’exécution des tests de non-régression.
Si le langage le permet, il est également possible (et souhaitable) d’exécuter:
- Un « linter » afin de valider le standard du projet;
- Les systèmes de métriques permettant de valider le projet.
Il est bien entendu possible d’en faire plus.
Les logiciels d’intégration continue
Voici une liste de service libre d’intégration continue non exhaustive pouvant être utilisée dans un projet de logiciel libre.
- Gitlab CI/CD
- Github Action
- Jenkins
- Travis CI
- Azure Pipelines
La procédure de configuration d’un logiciel d’intégration continue
Il est important de comprendre que chaque logiciel d’intégration continue a une procédure de configuration différente et il est impossible de toutes les montrer ici.
Par contre, ces procédures sont tout de même relativement semblables. Nous allons donc utiliser le logiciel Gitlab CI/CD pour cette présentation.
Afin d’utiliser Gitlab CI/CD, il est nécessaire d’avoir un dépôt (ou un clone du dépôt) du projet sur Gitlab.
Créer le fichier de configuration
Gitlab CI/CD utilise des fichiers Yaml afin de configurer le « pipeline » d’intégration continue. Afin de créer un nouveau fichier de configuration Yaml, il suffit de se rendre dans la section « CI/CD » dans le dépôt Gitlab.
Ensuite, pour générer initialement le script, vous pouvez soit utiliser un script modèle (« template ») fourni par Gitlab, ou bien utiliser le bouton « use template » pour avoir un modèle de base.
Il est également possible de créer manuellement le fichier Yaml à la racine du projet. Le fichier doit s’appeler exactement « .gitlab-ci.yml » (ne pas oublier le « . »).
Les configurations de bases
En fonction du type de langage à utiliser, on utilise des configurations différentes (avec ou sans compilation, linter, etc.) Nous ne les montrerons pas toutes ici. Nous n’allons que montrer la base. La documentation complète est accessible (en anglais seulement) ici. Donc, la première section du script est la section « stages » indiquant les différentes étapes à utiliser. Par exemple, la section « stage » suivante a trois (3) étapes: la compilation, les tests) et le déploiement:
stages:
- compilation
- test
- deploiement
Ensuite, nous pouvons créer autant de sections que nous souhaitons, mais pour que ces sections soient exécutées, nous devons spécifier dans quel « stage » ils doivent être utilisés. Par exemple:
stages:
- compilation
- test
- deploiement
compilation-job:
stage: compilation
script:
- echo Compilation
- ...
- echo Compilation terminé
unit-test-job:
stage: test
script:
- echo Exécution des tests
- ...
- echo Fin des tests
lint-test-job:
stage: test
script:
- echo Exécution du Linter
- ...
- echo Fin d'exécution du Linter
deploiement-job:
stage: deploiement
script:
- echo Déploiement
- ...
- echo Fin du déploiement
Il est à noter que les « … » dans les sections « script » représentent les lignes de commande à exécuter pour effectuer les étapes correspondantes.
Parfois, il est nécessaire de garder certaines informations entre les « stages » (par exemple, des fichiers compilés). Pour se faire, on utilise des « artifacts ». De plus, pour s’assurer que le « Gitlab Runner » exécute les « stages » dans le bon ordre, on peut utiliser des « dependencies ». Voici un exemple:
stages:
- compilation
- test
- deploiement
compilation-job:
stage: compilation
script:
- echo Compilation
- ...
- echo Compilation terminé
artifacts:
paths:
- build
unit-test-job:
stage: test
dependencies:
- compilation-job
script:
- echo Exécution des tests
- ...
- echo Fin des tests
lint-test-job:
stage: test
script:
- echo Exécution du Linter
- ...
- echo Fin d'exécution du Linter
deploiement-job:
stage: deploiement
dependencies:
- compilation-job
script:
- echo Déploiement
- ...
- echo Fin du déploiement
Utilisation de docker
L’exécution de la configuration du Gitlab CI/CD de base peut être suffisant pour des tâches simples ne nécessitant pas de logiciel (compilateur, interpréteur, etc.) ou librairie particulière. Par contre, si un système plus précis est nécessaire, il est possible d’exécuter les scripts dans des « dockers ». Tous les « dockers » accessibles gratuitement sur le site de DockerHub peuvent être utilisés. Également, il est possible de fournir l’image docker directement dans le dépôt ou bien utiliser un lien afin de télécharger l’image. Pour utiliser un « docker », il faut utiliser une information « image ».
Il est à noter qu’une nouvelle image de « docker » sera générée à chaque « stage » du « pipeline ». Il est donc nécessaire de configurer à nouveau le « docker ».
Voici un exemple:
stages:
- compilation
- test
compilation-job:
image: debian:latest
stage: compilation
script:
- echo "Préparation de l'image..."
- apt-get update
- apt-get install -y build-essential
- apt-get clean
- rm -rf /var/lib/apt/lists/*
- echo "Préparation terminé."
- echo "Compilation de la librairie..."
- make clean
- make all
- echo "Compilation terminée"
artifacts:
paths:
- bin
test-job:
image: debian:latest
stage: test
dependencies:
- compilation-job
script:
- echo "Préparation de l'image..."
- apt-get update
- apt-get install -y build-essential
- apt-get clean
- rm -rf /var/lib/apt/lists/*
- echo "Préparation terminé."
- echo "Compilation des tests..."
- cd test
- make clean
- make all
- echo "Exécution des tests..."
- bin/Release/test
- echo "Fin des tests."
Si la même image est utilisée pour tous les « stage », on peut spécifier l’image une seule fois. De plus, afin de ne pas dupliquer inutilement la préparation du docker, on peut utiliser l’information « extends » et mettre les instructions dans un « before_script » commun.
Voici un exemple:
image: debian:latest
stages:
- compilation
- test
.prepare-image:
before_script:
- echo "Préparation de l'image..."
- apt-get update
- apt-get install -y build-essential
- apt-get clean
- rm -rf /var/lib/apt/lists/*
- echo "Préparation terminé."
compilation-job:
stage: compilation
extends: .prepare-image
script:
- echo "Compilation de la librairie..."
- make clean
- make all
- echo "Compilation terminée"
artifacts:
paths:
- bin
test-job:
stage: test
extends: .prepare-image
dependencies:
- compilation-job
script:
- echo "Compilation des tests..."
- cd test
- make clean
- make all
- echo "Exécution des tests..."
- bin/Release/test
- echo "Fin des tests."
Les variables
Il y a trois types de variables utilisables dans un script Yaml de gitlab CI/CD:
- Variable prédéfinie
- Variable publique
- Variable cachée
Les variables prédéfinies sont des variables qui sont définies par le Gitlab Runner directement. Il y en a une grande quantité et on peut avoir leur documentation ici.
Les variables publiques sont généralement indiquées directement dans le fichier « .gitlab-ci.yml »; dans une section « variables » (soit dans un « stage » ou dans une section en tant que telle).
Voici un exemple utilisant des variables:
variables:
VARIABLE_GOLBALE: "Valeur de la variable globale"
stages:
- jobs
job_1:
stage: jobs
variables:
VARIABLE_LOCALE: "Valeur de la variable locale"
script:
- echo "Nom du stage courrant:" "$CI_JOB_STAGE"
- echo "La variable globale:" "$VARIABLE_GOLBALE"
- echo "La variable locale:" "$VARIABLE_LOCALE"
Les derniers types de variables sont les variables cachées. Ce type de variable nécessite de placer la valeur de ces variables directement dans les configurations privées du dépôt Gitlab. Il est généralement utile de créer ce type de variable lorsque certaines informations nécessaires à la compilation et aux tests ne peuvent pas être publiques. Le meilleur exemple de ce type de variables est les clés d’API Web.
Afin de déclarer une variable cachée il faut aller dans les configurations CI/CD du dépôt.
Ensuite, il faut se rendre dans la section « Variables »
Enfin, on peut ajouter des variables en utilisant le bouton « Add variable »
Les variables sont représentées de manière « Clé->Valeur » ou la clé est le nom de la variable et la valeur est sa valeur.
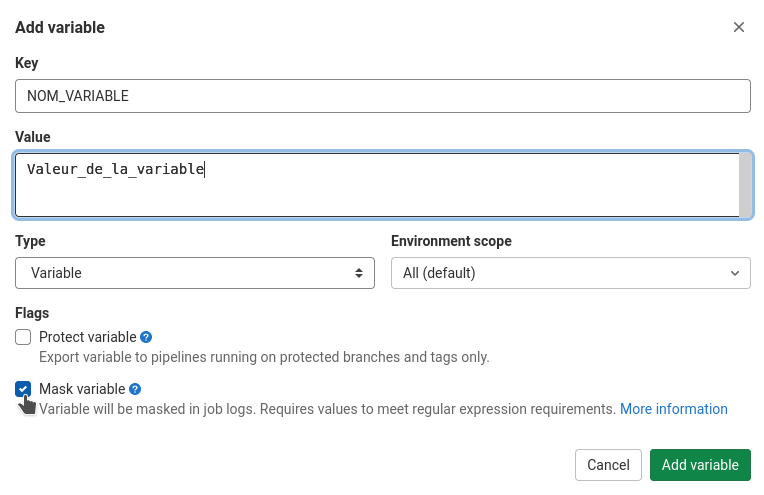
Il est important de noter que pour s’assurer que la valeur de la variable n’apparaisse pas dans les « logs » des exécutions de « pipeline », il faut cocher le « Mask ». Noter également que les variables « Mask » doivent respecter les critères suivants:
- Être sur une seule ligne,
- Être d’au moins 8 caractères,
- Être des caractères compatibles avec le standard Base64, en plus des caractères:
- « @ », « : », « . » et « ~ »
Auteur: Louis Marchand

Sauf pour les sections spécifiées autrement, ce travail est sous licence Creative Commons Attribution 4.0 International.