Introduction
L’héritage multiple est une fonctionnalité de la programmation orientée objet qui consiste à permettre à une classe d’hériter de plusieurs autres classes. L’héritage multiple permet une meilleure conception orientée objet en plus de s’assurer de diminuer au maximum la duplication de code et maximiser la réutilisabilité des classes. Malheureusement, l’héritage multiple ne fait pas l’unanimité dans la communauté des concepteurs de langages. La raison pour laquelle plusieurs concepteurs de langage ne s’aventurent pas dans l’implémentation de l’héritage multiple, c’est que certaines problématiques apparaissent lorsqu’on implémente cette mécanique. Il est possible de gérer ces problématiques, mais au coût d’un langage plus complexe.
Les bons côtés de l’héritage multiple
Dans cette section, je présenterai certains exemples montrant les avantages de l’héritage multiple.
Conception objet
Souvent, l’héritage est utilisé pour hériter de plusieurs types de classe « desing pattern », ou bien de classe abstraite permettant la gestion d’un certain aspect d’un sous-ensemble de classes. Il est par contre possible d’utiliser l’héritage multiple pour d’autres types de besoins. Voici un exemple simple:
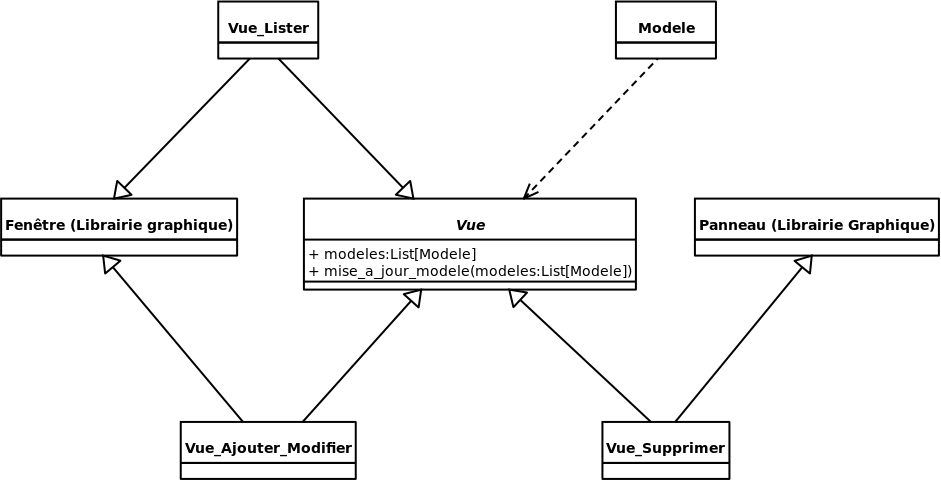
Dans cet exemple, la gestion du modèle (qui peut être n’importe quoi: Produit, Client, etc.) se fait dans les descendants de la classe Vue. Par contre, si on imagine que la Vue_Ajouter_Modifier et Vue_Lister sont créées sous forme de nouvelle page, mais que la Vue_Supprimer se fait simplement avec un panneau adjacent à la Vue_Lister, nous avons un cas ou l’héritage multiple peut être très logique à utiliser.
Diminution de la duplication de code
Voici comment Java gère les objets Comparable. Un objet Comparable est un objet qui peut être comparé avec un autre objet du même type en utilisant les opérations <, >, ==, !=, <= et >=. Pour garder l’exemple simple, je n’ai mis que 2 classes comparables (Integer et String). Il est important de comprendre qu’il existe une grande quantité de classes Comparable (voir: l’interface Comparable). Il est à noter que l’exemple est simplifié pour faire ressortir le point; la classe Comparable de Java ne contient qu’une méthode abstraite, mais qui sert autant à gérer la relation d’égalité (=) que les relations d’ordre (< et >). Mais le point demeure le même, mais en plus complexe.
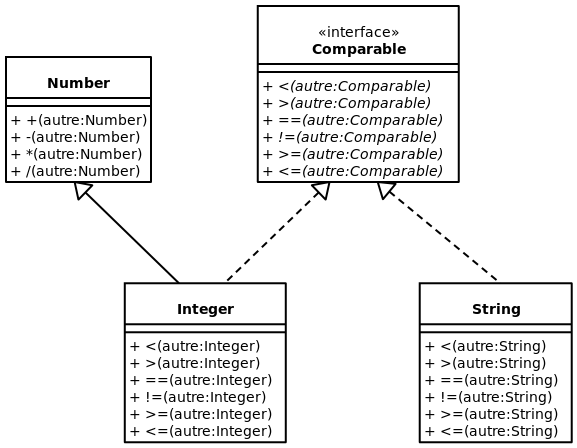
Le problème ici, c’est que la classe Integer hérite déjà de la classe Number, qui permet la gestion des opérations sur les nombres. Puisque Java ne gère pas l’héritage multiple, la classe Comparable doit être une interface. Par contre, mathématiquement, les classes enfants de Comparable devraient seulement implémenté une seule méthode (< ou >). Si nous supposons que la méthode plus petit (<) est implémentée (par l’enfant de Comparable), voici du pseudo-code qui montre comment implémenter les différentes autres méthodes de Comparable. Noter que l’objet en cours est représenté par cet_objet (en d’autres mots, si on compare à Java, « this = cet_objet »):
fonction >(autre:Comparable) faire
Retourne autre < cet_objet
fin
fonction !=(autre:Comparable) faire
Retourne (cet_objet < autre) ou (cet_objet > autre)
fin
fonction ==(autre:Comparable) faire
Retourne non(cet_objet != autre)
fin
fonction >=(autre:Comparable) faire
Retourne (cet_objet > autre) ou (cet_objet == autre)
fin
fonction <=(autre:Comparable) faire
Retourne (cet_objet < autre) ou (cet_objet == autre)
fin
On voit donc que la seule méthode de Comparable qui doit réellement être implémenté dans les Enfants de Comparable, c’est < (ou >). Le problème, c’est qu’en utilisant une interface au lieu d’une classe, on doit implémenter le code des autres méthodes (>, !=, ==, >= et <=) dans toutes les classes enfants de Comparable. En d’autres mots, le code ci-dessus doit être copié-collé intégralement dans chaque classe qui implémente comparable; ce qui augmente considérablement la duplication de code imposé par la librairie Java.
Pour comparer, voici ce qui est fait par la librairie Eiffel en utilisant l’héritage multiple:
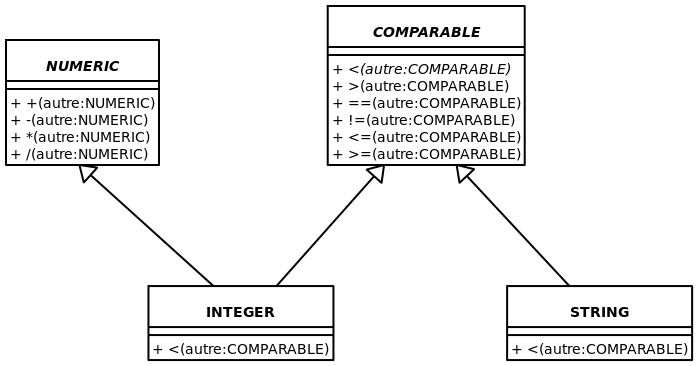
On peut donc voir que seulement la méthode plus petit (<) est implémentée dans les Enfants de Comparable. Toutes les autres méthodes sont implémentées directement dans la classe Comparable. On diminue donc au maximum la duplication de code imposée par la librairie Eiffel.
Maximiser la réutilisabilité des classes.
Afin d’avoir tous les avantages de l’héritage, il faut utiliser des classes. Par contre, il arrive que l’héritage simple empêche l’utilisation de classes qui pourrait être utile. Par exemple, voici un diagramme représentant une Vue représentant une fenêtre pouvant être observée:
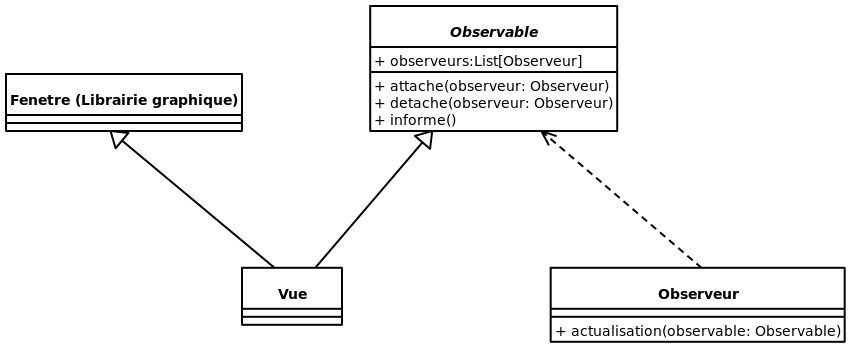
Le problème avec ce diagramme, c’est qu’elle nécessite l’héritage multiple pour fonctionner. Afin de construire la mécanique d’observable sans héritage simple, nous allons devoir nous passer de la classe Observable et de placer le code de gestion des Observeurs directement dans la classe Vue. Comme ceci:
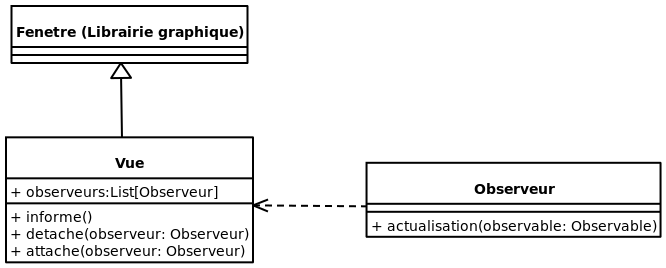
Le résultat est que si le responsable de la librairie d’Observable/Observeur fait des améliorations à sa classe Observable, la classe Vue ne bénéficiera pas de ces améliorations. De plus, si nous avons plusieurs classes Observable, nous ajoutons de la duplication de code (ce qui rejoint le point plus haut).
Les mauvais côtés de l’héritage multiple
Il va de soi que, s’il n’y avait que des avantages à l’héritage multiple, tous les langages l’auraient implémenté. Il est donc important de comprendre les problématiques que l’héritage multiple génère. Je vais présenter les 2 aspects problématiques majeurs de l’héritage multiple et je vais indiquer comment les langages implémentant l’héritage multiple ont contourné le problème.
Les conflits
On dit qu’il y a conflit lorsque, à cause de l’héritage multiple, la classe enfant se retrouve avec plusieurs méthodes différentes, avec la même signature. Par exemple:
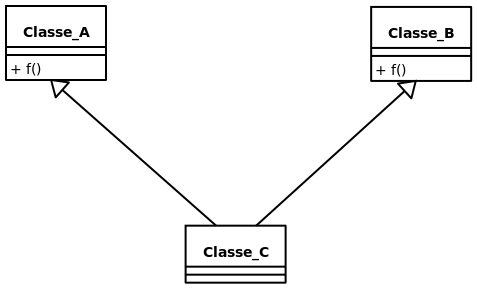
Donc, prenons le code suivant:
Classe_C monObjetC = ...;
monObjetC.f();
La question est donc: « Est-ce que c’est la méthode f() de Classe_A ou bien la méthode f() de Classe_B qui sera lancée? Il est impossible de répondre à cette question sans régler le conflit. Les différents langages ont différente manière re gérer les conflits. Voici des méthodes utilisées dans différents langages pour régler les conflits.
En Python
En Python, le langage ne gère aucun conflit. La méthode f() qui sera lancée est la première méthode trouvée par Python. Par exemple, si je prends cette classe:
class Classe_C(Classe_A, Classe_B):
La méthode f() qui sera lancée est la méthode f() de la Classe_A. Inversement, si je prends cette classe:
class Classe_C(Classe_B, Classe_A):
La méthode f() qui sera lancée est la méthode f() de la Classe_B.
Le gros problème avec cette mécanique, c’est que malgré l’absence de conflit, le fait de changer l’ordre d’héritage change la classe enfant, ce qui n’est pas acceptable au niveau orienté objet. En d’autres mots, une classe qui hérite de la Classe_A et de la Classe_B devrait être la même classe que si elle héritait de la Classe_B et de la Classe_A; ce qui n’est pas le cas ici.
En C++
Le langage C++ permet de gérer les conflits de la manière suivante. Lorsque le client de la classe fait l’appel de la fonction f(), il doit obligatoirement spécifier il s’agit du f() de quelle classe. Par exemple, le code suivant échouera:
Classe_C* objet_c = new Classe_C();
objet_c->f();
Si nous voulons le faire fonctionner, nous devrons utiliser le code suivant pour utiliser le f() de la Classe_A:
Classe_C* objet_c = new Classe_C();
objet_c->Classe_A::f();
et le code suivant pour utiliser le f() de la Classe_B:
Classe_C* objet_c = new Classe_C();
objet_c->Classe_B::f();
Une autre méthode que le client peut utiliser est d’utiliser un type différent pour la variable. Par exemple, ce code lancera le f() de la Classe_A:
Classe_A* objet_c = new Classe_C();
objet_c->f();
et le code suivant lancera le f() de la Classe_B:
Classe_B* objet_c = new Classe_C();
objet_c->f();
On peut également « typer » l’objet pour s’assurer d’utiliser la fonction recherchée. Par exemple, le code suivant lancera le f() de la Classe_A:
Classe_C* objet_c = new Classe_C();
((Classe_A*)objet_c)->f();
et le code suivant lancera le f() de la Classe_B:
Classe_C* objet_c = new Classe_C();
((Classe_B*)objet_c)->f();
Toutes ces méthodes, quoique fonctionnelles, ont été critiquées par les experts du domaine des langages de programmation puisqu’elles laissent le soin au client de la classe de choisir dans quelle classe parent trouver la méthode ou l’attribut à utiliser. De ce fait, les mécanismes de gestion de conflit contreviennent au principe d’encapsulation, un des piliers du concept orienté objet.
En Eiffel
Afin de respecter au maximum tous les principes objet, Eiffel s’est doté d’une section à part dans le code d’une classe afin de préciser tout ce qui a à préciser au niveau de l’héritage. Ainsi, des mécanismes plus complexes ont pu être développés afin de gérer élégamment les conflits. Le mécanisme le plus courant afin de régler un conflit consiste à renommer un ou plusieurs attributs ou méthodes afin de faire disparaître l’ambiguïté. Par exemple, ce code de la CLASSE_C donnera une erreur:
class
CLASSE_C
inherit
CLASSE_A
CLASSE_B
end
L’erreur nous indique que la CLASSE_C contient deux méthodes différentes avec le même nom. Nous pouvons donc renommer une des deux méthodes en utilisant la clause « rename »:
class
CLASSE_C
inherit
CLASSE_A
rename
f as f_de_a
end
CLASSE_B
end
Ce code compile sans problème puisqu’il n’y a plus de conflit. Il aurait également été possible de renommer les deux méthodes f. Par exemple:
class
CLASSE_C
inherit
CLASSE_A
rename
f as f_de_a
end
CLASSE_B
rename
f as f_de_b
end
end
Dans le cas ou nous ne voudrions seulement une des deux méthodes des classes parents, nous pourrions tous simplement demander au compilateur d’oublier la méthode qui ne nous intéresse pas avec la clause « undefine ». Par exemple:
class
CLASSE_C
inherit
CLASSE_A
CLASSE_B
undefine
f
end
end
Une dernière possibilité serait de redéfinir la méthode f(). Cette méthode permet également de créer une seule méthode f() dans CLASSE_C qui lancerait autant la méthode f() de CLASSE_A et la méthode f() de CLASSE_B avec le mot clé « precursor ». Par exemple:
class
CLASSE_C
inherit
CLASSE_A
redefine
f
end
CLASSE_B
redefine
f
end
feature
f
do
Precursor {CLASSE_A}
Precursor {CLASSE_B}
end
end
Le problème du diamant
Le problème du diamant est le problème le plus important dans le principe d’héritage multiple. Il n’existe pas de mécanisme vraiment facile et élégant à ce jour pour gérer ce problème. Il est par contre important de spécifier qu’heureusement, il est très rare que ce problème arrive réellement dans un programme réel.
Ce problème arrive lorsqu’une classe parent spécifie une méthode, que plusieurs de ses classes enfants redéfinissent cette méthode et que finalement, une classe hérite de ces classes enfants. Voici le diagramme de classe représentant cette situation:
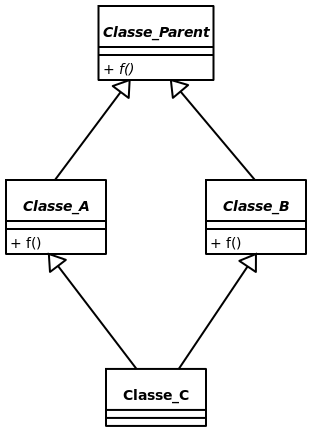
Cette mécanique semble similaire au conflit préciser plus haut, mais la subtilité repose dans un cas d’utilisation spécifique. Pour la représenter, voici un exemple Eiffel qui utilise la mécanique de « rename » indiquée plus haut. Cela devrait vous montrer d’où vient la problématique du problème du diagramme.
Premièrement, voici la CLASSE_PARENT:
deferred class
CLASSE_PARENT
feature
f
deferred
end
end
Les deux classes enfants seront les suivantes:
class
CLASSE_A
inherit
CLASSE_PARENT
feature
f
do
print("A%N")
end
end
class
CLASSE_B
inherit
CLASSE_PARENT
feature
f
do
print("B%N")
end
end
Ensuite, la classe qui hérite des deux classes enfants:
class
CLASSE_C
inherit
CLASSE_B
rename
f as f_de_b
end
CLASSE_A
rename
f as f_de_a
end
end
On peut voir que, malgré qu’il y a clairement un conflit entre la CLASSE_A et la CLASSE_B, ce conflit est réglé en utilisant les clauses « rename ». Maintenant, prenons l’utilisation de la part du client. Si j’utilise le code suivant:
make
local
objet:CLASSE_C
do
objet := create {CLASSE_C}
objet.f_de_a
end
On voit que la méthode f de la CLASSE_A sera utilisée. De la même manière, dans le code:
make
local
objet:CLASSE_C
do
objet := create {CLASSE_C}
objet.f_de_b
end
on voit que la méthode f de la CLASSE_B sera utilisée. De manière moins évidente, dans le code:
make
local
objet:CLASSE_A
do
objet := create {CLASSE_C}
objet.f
end
le f de la CLASSE_A sera utilisé, puisque la variable objet est de type CLASSE_A. De la même manière, dans le code:
make
local
objet:CLASSE_B
do
objet := create {CLASSE_C}
objet.f
end
le f de la CLASSE_B sera utilisé.
Finalement, et c’est ici que le problème du diamant prend tout son sens, si on prend le code suivant:
make
local
objet:CLASSE_PARENT
do
objet := create {CLASSE_C}
objet.f
end
est-ce qu’il est possible de savoir quel f sera utilisé ? En effet, puisque la méthode f de la CLASSE_PARENT est abstraite, il faut aller voir dans les classes enfants pour connaître l’implémentation de la méthode. Par contre, il y a deux implémentations différentes de la méthode f dans les enfants de CLASSE_PARENT. Puisque la CLASSE_PARENT est le parent de la CLASSE_A et de la CLASSE_B, et qu’en orientée objet, un parent ne doit avoir aucune dépendance envers leurs enfants (les parents ne connaissent pas les enfants). Logiquement, il pourrait être possible que la classe parent soit dans une certaine librairie et que les classes enfants ne sont pas accessible à partir de cette librairie. Encore une fois, la solution de ce problème est différente en fonction du langage utilisé.
En Python
La solution en Python est le même que pour la solution des conflits présentée plus haut. Python utilisera la première méthode trouvée dans la liste des méthodes de l’objet. Voir plus haut pour les inconvénients de cette solution.
En C++
Encore une fois, la solution en C++ est similaire au problème du conflit présenté plus haut. C’est-à-dire qu’il faut préciser dans quelle classe l’implémentation se trouve dans l’implémentation afin de retirer l’ambiguïté. Par exemple:
Classe_Parent* objet = new Classe_C();
objet->Classe_A::f();
On voit que l’ambiguïté est retiré par le fait de spécifier le CLASSE_A dans l’appel de méthode. Il est également possible d’utiliser le « typage » comme ceci:
Classe_Parent* objet = new Classe_C();
((Classe_A*)objet)->f();
Encore une fois, malgré que cette méthode est généralement fonctionnelle, un très grand problème ressort de ces mécanismes. En effet, la règle du concept orientée objet précisant que les classes ne devraient pas connaître leurs enfants devrait également s’appliquer aux clients de la classe. En d’autres mots, la classe qui utilise une variable de type Classe_Parent ne devrait pas prendre en considération que cette Classe_Parent a des enfants. De manière encore plus importante, du code complètement fonctionnel peut se retrouver non fonctionnel à cause de l’ajout d’héritage. Par exemple, prenons une librairie logicielle indépendante qui contient une classe abstraite avec une méthode (similaire la notre Classe_Parent) et une autre classe de la librairie utilise la méthode de cette classe abstraite. Les classes de cette librairie logicielle peuvent être correctement compilées sans erreur. Par la suite, on inclut cette librairie dans un autre projet logiciel et dans ce projet, on ajoute les classes enfants qui créé le « desing » en diamant. On obtient donc que le code qui ne compile pas ne se trouve pas dans le projet en tant que tel, mais dans la librairie qui compilait correctement avant d’avoir été incluse au projet. Cette problématique ne brise pas simplement les concepts orientés objet, mais bien les concepts de bases des dépendances logiciels en général.
En Eiffel
Afin de respecter les principes orientés objet au maximum, Eiffel permet une autre section dans sa clause d’héritage. Cette clause est la clause « select » et cette clause ne s’applique uniquement que dans le cas d’un problème du diamant. Il est donc assez rare de voir cette clause apparaître dans un code Eiffel. Donc, si je règle le problème du diamant présenté plus haut, je ne fais qu’ajouter la clause « select » suivante:
class
CLASSE_C
inherit
CLASSE_B
rename
f as f_de_b
end
CLASSE_A
rename
f as f_de_a
select
f_de_a
end
end
Cette clause indique au compilateur que, s’il se trouve avec le dernier exemple « make » présenté plus haut, la méthode f de la CLASSE_A (ou f_de_a) sera utilisée.
Ce mécanisme respecte le principe orienté objet puisqu’elle est spécifiée dans le dernier enfant de l’héritage du « désing » en diamant et que, puisque les enfants peuvent connaître leurs parents, le principe de dépendance est respecté.
Héritage réppétée
Lorsqu’une classe hérite directement plusieurs fois de la même classe, on a un cas d’héritage répété.
Autre qu’Eiffel, aucun langage (que je connais) n’implémente ce type d’héritage.
Grâce aux mécaniques de « rename » et de « select » de Eiffel, il est possible d’utiliser, de manière assez efficace, l’héritage répété en Eiffel. D’ailleurs, les classes « TWO_WAY_CHAIN_ITERATOR » et « CURSOR_TREE_ITERATOR » utilisent l’héritage répété.
À propos des interfaces
Aujourd’hui, la majorité des langages de programmation hérite des langages C et C++. Lorsque les créateurs de langage comme Java et C# ont développé leurs langages, ils ont introduit le principe d’interface pour remplacer l’héritage multiple dans leur langage. Cette section présente d’où vient l’idée des interfaces et à quelle mesure ça remplace l’héritage multiple par classes.
Historique
Lors des sections précédentes, nous avons vu que la gestion des conflits en C++ (particulièrement dans un cas de « desing » en diamant) était déficiente et brisait beaucoup de concepts importants dans le domaine de la programmation. Voir la section précédente pour plus de détails.
Afin de régler ces problématiques, une règle non écrite et non officielle a commencé à circuler dans la communauté de programmeur C++. La règle est la suivante. Dans l’arbre d’héritage d’une classe, une seule branche d’héritage peut contenir des classes effectives et des classes abstraites contenant des attributs ou des méthodes implémentées. L’héritage multiple peut être utilisé, mais seulement si toutes les autres branches d’héritage contiennent uniquement des classes abstraites qui contiennent uniquement des méthodes abstraites. Cette règle a donné naissance au patron conceptuel d’interface.
Puisque les langages comme Java et C# sont grandement basés sur C et C++, ils ont décidé d’inclure cette règle non écrite dans le langage en permettant uniquement l’héritage simple et de l’héritage multiple d’interfaces.
En d’autres mots, la principale raison pour laquelle les langages populaires d’aujourd’hui comme Java et C# n’ont pas tous les avantages que l’héritage multiple propose, est que C++ a mal implémenté ce type d’héritage.
Avantages et limites des interfaces
L’héritage multiple sous la forme d’interface a tout de même certains avantages. En effet, en plus d’éviter complètement les conflits dans l’héritage, elle permet l’utilisation du polymorphisme. En effet, sans ce type d’interface, des « desing » comme Observeur, Médiateur, Listener, etc. ne serait pas possible.
Il est par contre important de noter les limites de ce type d’héritage. En effet, comme nous l’avons vu plus haut, l’héritage par interface diminue significativement la réutilisabilité des classes et oblige l’utilisation de duplication de code dans certains contextes. Également, de manière structurelle, le langage (et potentiellement toutes les classes) se retrouve avec deux arbres d’héritage indépendants, ce qui peut complexifier la documentation et l’utilisation des classes du système.
Retour
Auteur: Louis Marchand

Sauf pour les sections spécifiées autrement, ce travail est sous licence Creative Commons Attribution 4.0 International.